활용 문제 : www.acmicpc.net/problem/2357
2357번: 최솟값과 최댓값
N(1 ≤ N ≤ 100,000)개의 정수들이 있을 때, a번째 정수부터 b번째 정수까지 중에서 제일 작은 정수, 또는 제일 큰 정수를 찾는 것은 어려운 일이 아니다. 하지만 이와 같은 a, b의 쌍이 M(1 ≤ M ≤ 100
www.acmicpc.net
백준 문제와 테스트 케이스를 이용해서 속도 비교를 해 보았습니다.




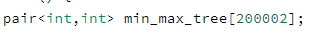

pair의 경우 객체 메서드 생성에 의해 조금 느린 것을 볼 수 있지만 거의 차이가 보이지 않아 간단한 벤치마킹 코드를 작성해서 비교해 보았습니다.
백준 테스트 케이스를 얻을 수 없어서 std::sort 함수를 통해 성능을 비교하도록 하겠습니다. sort 함수에서 2차원 배열을 사용하기 위해서는 연산자 오버라이드가 복잡하여 성능 측정을 할 수 없으므로 생략하도록 하겠습니다.
2차원 배열, 구조체, 2개의 1차원 배열 사용은 거의 차이가 없습니다.

struct 사용 시 보통 2초 정도가 걸리며 pair 사용 시 거의 1.5배에 가까운 4초 대의 결과가 나옵니다. pair의 연산자 또한 지정하여 계산을 다시 해 보았습니다.

결과 pair을 사용했을 때 시간이 줄긴 하였지만 pair의 경우 객체이기 때문에 추가로 시간이 소모되는 것을 볼 수 있습니다. 따라서 swap 메서드가 필요하지 않은 경우라면 struct를 선언하여 사용하는 것이 속도를 줄일 수 있는 것으로 볼 수 있습니다.
코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
#include <iostream>
#include <random>
#include <algorithm>
#include <ctime>
#include <Windows.h>
using namespace std;
#define MAX_SIZE 1000000
typedef struct node {
int first, second;
bool operator < (const node &b) const {
if (first != b.second) return first < b.first;
return second < b.second;
}
}node;
void use_struct(node ary[], int data_1[], int data_2[]) {
double time;
bool b;
__int64 freq, start, end;
BOOL condition;
if (condition = QueryPerformanceFrequency((_LARGE_INTEGER*)&freq))
QueryPerformanceCounter((_LARGE_INTEGER*)&start);
//
for (int i = 0; i < MAX_SIZE; i++) {
ary[i].first = data_1[i];
ary[i].second = data_2[i];
}
sort(ary, ary + MAX_SIZE);
//
if (condition) {
QueryPerformanceCounter((_LARGE_INTEGER*)&end);
time = (float)((double)(end - start) / freq * 1000);
printf("struct time : %lf\n", time);
}
}
bool comp (pair<int, int> &a, pair<int,int> &b) {
if (a.first != b.second) return a.first < b.first;
return a.second < b.second;
}
void use_pair(pair<int, int> ary[], int data_1[], int data_2[]) {
double time;
bool b;
__int64 freq, start, end;
BOOL condition;
if (condition = QueryPerformanceFrequency((_LARGE_INTEGER*)&freq))
QueryPerformanceCounter((_LARGE_INTEGER*)&start);
//
for (int i = 0; i < MAX_SIZE; i++) {
ary[i].first = data_1[i];
ary[i].second = data_2[i];
}
sort(ary, ary + MAX_SIZE, comp);
//
if (condition) {
QueryPerformanceCounter((_LARGE_INTEGER*)&end);
time = (float)((double)(end - start) / freq * 1000);
printf("pair time : %lf\n", time);
}
}
int main() {
int data_1[MAX_SIZE], data_2[MAX_SIZE];
node st_ary[MAX_SIZE];
pair<int, int> pr_ary[MAX_SIZE];
mt19937 gen(1111);
uniform_int_distribution<int> dis(0x80000000, 0x7fffffff);
for (int i = 0; i < MAX_SIZE; i++) {
data_1[i] = dis(gen);
data_2[i] = dis(gen);
}
use_struct(st_ary, data_1, data_2);
use_pair(pr_ary, data_1, data_2);
}
|
cs |
'스터디 > C++' 카테고리의 다른 글
| [C++] 절댓값 빠르게 구하기 (0) | 2021.02.20 |
|---|